Data Spaces und Use Cases
DIO lädt die Stakeholder:innen zur Entwicklung von Data Spaces und Use Cases ein, um branchenspezifische und industriesektorale Problemstellungen zu lösen.
Use Cases fokussieren einen Teilbereich einer Domäne und ermöglichen den Austausch, die Nutzung und den Handel von Daten in einem klar abgegrenzten Teilgebiet. Sie sollen auf einem virtuellen Datenmarkt gehandelt und schließlich gemeinsam genutzt werden.
DIO Data Spaces
Arbeitsgruppen, Data Spaces und Use Cases helfen dabei, Herausforderungen im Bereich Daten konkret und Domänen spezifisch zu betrachten. Data Spaces fokussieren sich auf übergeordnete Domänen (Wirtschaftsbereiche, Industriesektoren oder sonstige fachliche Anwendungsfelder), mit einer dezentralen Dateninfrastruktur, auf der Use Cases aufbauen können. In einem Data Space werden Daten unter Wahrung der Datensouveränität für potenzielle innovative Dienste verfügbar gemacht.
Green Data Hub Data Spaces
Neben den Data Spaces der DIO wird im Rahmen des Green Data Hubs in vier Data Spaces gearbeitet, die sich dem Thema Data for Sustainability widmen.
DIO Use Cases
Use Cases sind themenspezifische Plattformen innerhalb eines Data Spaces.
Was ist ein Data Space?
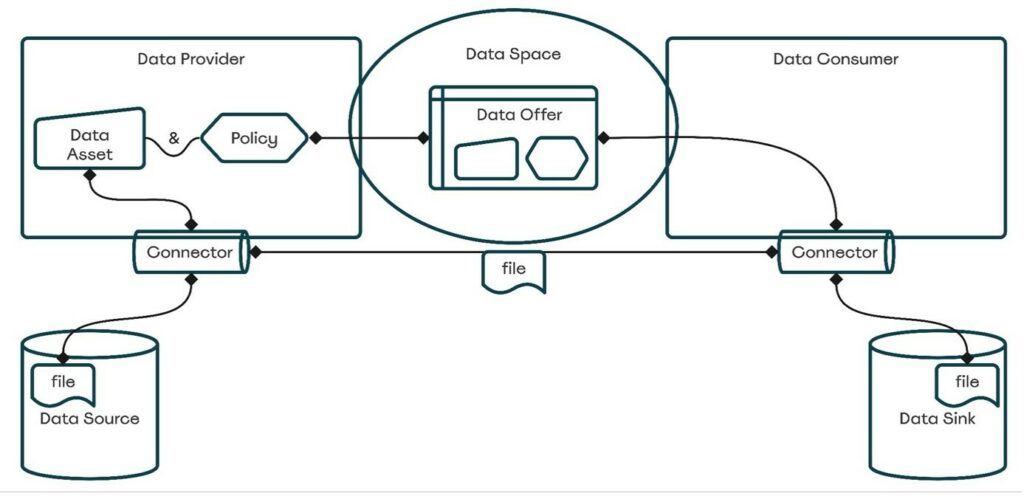
Ein Data space, auch in Folge als Datenraum bezeichnet, bezieht sich auf eine Art von vertrauenswürdigen Datenbeziehung zwischen Partner:innen & Organisationen, die jeweils die gleichen Standards und Regeln für die Speicherung, Verarbeitung und gemeinsame Nutzung ihrer Daten anwenden. Von wichtigster Bedeutung für das Konzept eines Datenraums ist jedoch, dass die Daten nicht zentral, sondern an der jeweiligen Quelle verteilt gespeichert werden und daher nur bei Bedarf im Rahmen von gemeinsamen Use Cases kollektiv genutzt werden. Datenräume fokussieren sich auf Domänen (Wirtschaftsbereiche, Industriesektoren oder sonstige fachliche Anwendungsfelder) und stellen Metadaten unter Wahrung der Datensouveränität, das heißt der größtmöglichen Kontrolle und Herrschaft über die eigenen Daten, für potenzielle innovative Anwendungen zur Verfügung. Domänenspezifische Datenräume können sich auch mit anderen Datenräumen verbinden (föderieren), wie beispielsweise ein Datenraum für Land- und Forstwirtschaft und einer für Energie oder EU-Green Deal.
Aktuell werden gezielt Technologien entwickelt, die die Realisierung von Datenräumen ermöglichen sollen. Dabei zielt beispielsweise Gaia-X oder IDSA darauf ab, eine föderierte offene Dateninfrastruktur zu schaffen, die auf europäischen Werten basiert. Die Aufgabe von Gaia-X und IDSA besteht darin, eine Architektur für die gemeinsame Nutzung von Daten zu entwerfen und umzusetzen, die aus gemeinsamen Standards für die gemeinsame Nutzung von Daten, bewährten Verfahren, Werkzeugen und Governance-Mechanismen besteht.
Elemente eines Data Spaces:
Digital Data Contracts
Digital Data Contracts sind Vereinbarungen, die Regeln für das Sammeln, Speichern, Teilen und Verwenden von Daten zwischen Participants (Teilnehmer:innen) innerhalb eines Data Spaces festlegen. Diese Vereinbarungen legen klare Richtlinien für die Teilnehmer:innen fest und funktionieren ähnlich wie rechtliche Verträge bei physischen Transaktionen. Alle Teilnehmer:innen, i.e. Datenanbieter, Datenverbraucher und Dateneigentümer, müssen diesen Vereinbarungen zustimmen, um einen Datenaustausch zu ermöglichen. In Digital Contracts werden zum Beispiel die Rechte an und den Zugriff auf die Daten transparent definiert, damit die Dateneigentümer die Kontrolle über ihre Daten behalten und der Rahmen für die Datenverwendung geklärt ist.
Connectoren und Hubs
Der EDC als Konnektor des Eclipse Data Space Components Frameworks setzt eine Rahmenvereinbarung für den souveränen, organisationsübergreifenden Datenaustausch basierend auf International Dataspaces Standard sowie relevante Prinzipien Gaia-X um. Der Konnektor ist erweiterbar konzipiert, um alternative Protokolle zu unterstützen und in verschiedene Ökosysteme integriert zu werden. Ziel ist der Aufbau einer dezentralen Softwarekomponente auf Seiten der jeweiligen Partner:innen, die die erforderlichen Fähigkeiten zur Teilnahme an einem Datenraum bündelt und Peer-to-Peer Verbindungen zwischen Teilnehmer:innen ermöglicht. Hier liegt der Fokus insbesondere auf der Datensouveränität der unabhängigen Firmen. Die dafür notwendige Funktionalität bündelt das OpenSource Projekt Eclipse Data Space Components. Mit dem EDC wurde ein Framework mit mehreren Komponenten, welche als Referenzimplementierung des IDS Protokollstandards dienen sollen geschaffen. Mit Hilfe dieser Komponenten können eine Vielzahl an flexiblen Dataspace Konnektoren entwickelt werden, welche die folgenden Architekturprinzipien umsetzen:
• Einfach: Erhaltung eines kleinen und effizienten Kerns mit so wenig externen Abhängigkeiten wie möglich.
• Interoperabel: Unabhängigkeit von Plattformen und Ökosystemen.
• Dezentral: Softwarekomponenten mit den erforderlichen Fähigkeiten zur Teilnahme an einem Datenraum befinden sich jeweils auf Seiten der Partner, Daten werden nur zwischen den vereinbarten Punkten ausgetauscht.
• Datenschutz ist wichtiger als Data Sharing: zu übertragende Daten sind grundsätzlich mit Policies über Verträge verbunden; eine Übertragung ohne Vertrag ist nicht möglich.
• Separierung von Metadaten und Daten: ermöglicht hohe Durchsatzraten für den eigentlichen Datentransfer.
• Automatisiert: Möglichst alle Prozesse, beginnend mit der Feststellung der Identität, über die Sicherstellung der vertraglich vereinbarten Regularien bis hin zur Datenübertragung laufen automatisiert.
• Standardisiert: Existierende Standards und Protokolle (Gaia-X + IDSA), werden so weit wie möglich verwendet.
Der Hauptunterschied zwischen dem EDC und anderen Konnektoren ist die Aufteilung der Kommunikation in einen Kanal für die Metadaten und einen für den eigentlichen Datenaustausch. Der Kanal für die Daten unterstützt über sogenannte Data Plane Extensions verschiedene Übertragungsprotokolle. Die Metadaten werden dabei direkt über die Schnittstelle des EDC übertragen, während der eigentliche Datenaustausch dann über die passende Channel Extension stattfindet. Auf diese Weise wird ein hoch skalierbarer Datenaustausch ermöglicht.
Federated Data & Service Catalogue
Der Föderierte Katalog ist ein indiziertes Verzeichnis, das die Suche und Auswahl von Anbietern und deren Serviceangeboten zu ermöglichen. Die Selbstbeschreibungen sind die Informationen, die die Teilnehmer über sich selbst und über ihre Dienste in Form von Eigenschaften und Attributen.
Die Semantik in einem Dataspace
Semantische Interoperabilität (SI) spielt eine wichtige Rolle beim Aufbau einer föderierten Dateninfrastruktur zur Unterstützung um Daten und Datenservices maschinell (über Konnektoren) mit dem gleichen Verständnis kommunizieren zu lassen.
SI ist definiert als „die Fähigkeit von Computersystemen, Daten mit eindeutiger, gemeinsamer Bedeutung zu übermitteln. Die Semantische, als auch syntaktische Interoperabilität gewährleistet, dass das dokumentierte Datenformat und die Bedeutung der ausgetauschten Daten und Informationen während des gesamten Austauschs zwischen den Parteien erhalten und verstanden werden. Mit anderen Worten, ‚was gesendet wird was gesendet wird, ist das, was verstanden wird“.
Konkrete Maßnahmen zur Sicherstellung der semantischen Interoperabilität bestehen unter anderem in dem gemeinsamen Aufbau bzw. Adaptierung und Erweiterung vorhandener Datenmodelle (FeatureTypeCatalouge) und Nutzung gemeinsamer Terminologien als kontrolliertes Vokabular, z.B. AgroVoc. Diese Elemente sollten über ein Management System als Vokabularservices bereitgestellt werden, in denen der gesamte Life Cycle als Provenance Informationen abgebildet werden kann. Darüber hinaus sollten auch “mapping scripts” für die Harmonisierung und Skalierung heterogener Eingangsdaten erarbeitet und in einem solchen System zugänglich sein.
Rulebook
Unternehmen können durch die Nutzung eines Dataspaces Datensouveränität erlangen und mit der dabei eingehenden Datenhoheit einen zusätzlichen Wettbewerbsvorteil generieren.
Functional requirements
Dateninhaber streben danach, die Kontrolle über die Daten zu erhalten. Kontrolle ist bei der internen Datenverwaltung wichtig, jedoch spielt sie eine noch wesentlichere Rolle bei der gemeinsamen Nutzung der Daten mit anderen Teilnehmern.
Die Kernfunktion eines Data Spaces besteht darin, Vertrauen zwischen den einzelnen Teilnehmern zu vermitteln und verfügbare Datenverträge zwischen diesen auszuverhandeln. Dabei spielt der Grad des Vertrauens eine relevante Komponente, einige Teilnehmer können bereits vor Einstieg in den Data Space durch frühere Beziehungen Vertrauen aufgebaut haben, andere haben noch keine Beziehung zueinander und müssen diese erst eingehen. Dabei ist innerhalb der Data Spaces keine Grenze gesetzt und ermöglicht sogar einen Austausch zwischen direkten Konkurrenten. Eine wichtige Rolle kommt dabei den Data Space Konnektoren zu, die eine gemeinsame Nutzung von Datenbeständen koordinieren und für Teilnehmer erleichtern, indem sie die vom Datenanbieter festgelegten Anforderungen durchsetzen.
Diese Konnektoren behandeln Richtlinien, Konfigurations- und andere Metadaten-Artefakte, die in jeder Cloud-Infrastruktur entweder vor Ort oder auf einem Edge-Gerät ausgeführt werden können.
Die gemeinsame Datennutzung beschränkt sich nicht darauf, Daten von einem Teilnehmer zum anderen zu senden, sondern kann auch komplexer sein.
Establishing trust
Vertrauen ist in einem Data Space von grundlegender Bedeutung. Daten können nur dann einen nachhaltigen Wert schaffen, wenn sie mit anderen Daten interagieren und bei der Entscheidungsfindung unterstützen können. Fehlt jedoch das Vertrauen unter den Teilnehmern, kann diese Interaktion nicht stattfinden.
Data Spaces können hier eine Grundlage schaffen und kontextspezifisches Vertrauen schaffen, wo zuvor kein Vertrauen bestand oder dieses schwer herzustellen ist, wie z.B. bei Teilnehmern in einem gemeinsamen Wettbewerb. Vertrauen wird dabei über die Attribute der Teilnehmer bewertet und mit den Anforderungen, Richtlinien und Regeln des Data Spaces abgeglichen. Dazu legt der Data Space Richtlinien fest, die der einzelne Bewerber erfüllen muss, um ein vertrauenswürdiger Teilnehmer zu werden.
Policies/Richtlinien
Richtlinien gewährleisten ein vertrauenswürdiges Datenökosystem innerhalb eines Data Spaces. Dabei werden sie auf mehreren Ebenen an fast allen Interaktionspunkten eingesetzt. Die beiden wichtigsten Richtliniengruppen, die für die Funktionalität des Datenraums sind, sind die Zugriffsrichtlinien (regeln den Zugang zu Verträgen) und die Vertragsrichtlinien (die die Vertragsbedingungen und die Nutzung von Daten regeln).
Richtlinien innerhalb eines Data Space können drei mögliche Einschränkungen ausdrücken: Verbote, Verpflichtungen und Erlaubnisse. Beschränkungen, die eine Regel ausdrücken, können zu komplexeren Regeln kombiniert werden, die dann eine geltende Richtlinie bilden können. Beispielsweise kann eine Gruppe von Data Space-Teilnehmern den Zugang zu ihren Daten nur Teilnehmern gestatten, die demselben Branchenverband angehören, die Verarbeitung von Daten unter der Bedingung zulassen, dass nur anonymisierte Ergebnisse erzeugt werden und anschließend die Weitergabe der Ergebnisse an Dritte zur Verarbeitung gestatten, wenn sie einer Reihe von ISO-Normen entsprechen.
Bekommt ein Teilnehmern Zugang zu einem Datenvertragsangebot, wird die nächste Gruppe von Richtlinien relevant. Dieses Datenvertragsangebot kann über Vertragsrichtlinien (Contract Policies) verfügen und festlegen, welche Attribute für einen Datenvertrag erforderlich sind. In den Vertragsrichtlinien werden dabei die Attribute der Teilnehmer überprüft, die bei der Vertragsverhandlung angegeben werden müssen. Diese Richtlinien stellen sicher, dass nur Unternehmen mit bestimmten Eigenschaften, die sie nachweislich belegen können, beitreten können.
Vertraglich festgehalten können auch die Richtlinien für den Transportmechanismus für die Übertragung von Datenbeständen werden.
Auch Nutzungsrichtlinien können in den Vertragsrichtlinien festgehalten werden, diese treten nach der Übertragung der Daten in Kraft und regeln, wie die Daten von der empfangenden Partei genutzt werden dürfen.
Attribute based trust
Ein Aufbau von Vertrauen auf der Grundlage von Attributen ist ebenso ein Kontrollmechanismus. Der Grad des Vertrauens eines Teilnehmers wird durch die Bewertung der Attribute des Teilnehmers, des Dienstvertrags, des Datenbestands und der Umgebungsattribute bestimmt. So wird das potenzielle Risiko der gemeinsamen Nutzung von Daten mit einem anderen Teilnehmer bewertet. Diese Vertrauensstufe basiert auch auf den Teilnehmerattributen, den Attributen des Datenraums und den Attributen der im Datenraum gemeinsam genutzten Daten sowie auf den anwendbaren Vertrauensankern und Vertrauenrahmen.
Attributbasiertes Vertrauen bietet ein dynamisches, kontext- und risikobewusstes Vertrauensmodell, das eine präzise Kontrolle durch die Einbeziehung von Attributen aus vielen verschiedenen Informationssystemen mit angepassten Regeln ermöglicht. Es bietet den Teilnehmern die nötige Flexibilität, verschiedene Implementierungen auf der Grundlage der Anforderungen zu stellen und auch zu verwenden.
Reference Architecture Model (RAM)
Das empfohlene architekturmodell definiert grundlegende Konzepte für den souveränen Datenaustausch. Dabei konzentriert es sich auf die allgemeinen Konzepte, Funktionen und Prozesse, die zur Schaffung eines sicheren Netzwerks vertrauenswürdiger Daten erforderlich sind.
Dabei befindet es sich auf einer höheren Ebene als die üblichen Architekturmodelle konkreter Softwarelösungen.
Das Modell besteht dabei aus fünf Schichten:
- Die geschäftliche Ebene:
Sie spezifiziert die verschiedenen Rollen, die die einzelnen Teilnehmer einnehmen können und weiters auch die wichtigsten Aktivitäten und Interaktionen, die mit jenen Rollen verbunden sind
- Die Funktionsschicht:
Definiert die funktionalen Anforderungen an das IDS und die daraus abzuleitenden Merkmale.
- Die Prozessschicht:
Spezifiziert die Interaktionen zwischen den Komponenten und bietet gleichzeitig eine dynamische Sicht auf das RAM.
- Die Informationsschicht:
Definiert ein konzeptionelles Modell, das sowohl die statischen als auch die dynamischen Aspekte der IDS-Bestandteile unter Verwendung von Datenverknüpfungsprinzipien beschreibt.
- Die Systemschicht:
Befasst sich mit der Zerlegung der logischen Softwarekomponenten unter Berücksichtigung von Apsekten wie Integration, Konfiguration, Einsatz und Erweiterbarkeit dieser Komponenten.
Über all diese Schichten empfiehlt es sich drei Perspektiven zu implementieren: Sicherheit, Zertifizierung und Governance.